La librairie Pandas, la meilleure librairie pour les données financières
Maîtrisez Pandas pour la finance : créez et manipulez DataFrame et Series, importez CSV/Excel, nettoyez vos données et réalisez analyses financières efficaces.
Dans le secteur de la finance, on peut affirmer sans trop prendre de risque que le logiciel le plus utilisé est Excel. Dans cet épisode, nous allons découvrir une librairie qui va nous permettre de faire tout ce qui peut se faire en Excel en mieux. 📊
Introduction à Pandas
Pandas est une bibliothèque Python très populaire qui fournit des structures de données flexibles et des outils d'analyse des données. Elle est particulièrement adaptée pour traiter des données financières et est largement utilisée dans la communauté financière. Pandas est construite sur la bibliothèque NumPy, qui est une bibliothèque de calcul scientifique pour Python.
Dans cette partie, nous allons explorer les fonctionnalités de base de Pandas, y compris la création, la manipulation et l'analyse de données financières.
Installation et importation de Pandas
Nous découvrons avec Pandas l’utilisation de librairie/bibliothèque. En effet, le langage de programmation Python permet d’importer des librairies qui facilitent grandement le développement. La diversité des librairies disponibles sur Python est une de ses plus grandes forces. Ces librairies s’installent grâce au gestionnaire de bibliothèque pip qui a dû être installé lors de l’installation de Python.
Pour utiliser Pandas, il faut d'abord l'installer en exécutant la commande suivante dans votre terminal ou invite de commandes :
pip install pandas
Une fois installé, vous pouvez importer Pandas dans votre script Python en ajoutant cette ligne :
import pandas as pd
L'alias "pd" est couramment utilisé pour Pandas, c’est un raccourci qui nous permet de diminuer le nombre de caractères à taper par la suite.
Les objets DataFrame et Series
Les principaux objets de Pandas sont les DataFrame et les Series. Un DataFrame est une structure de données bidimensionnelle, similaire à une table de base de données ou un classeur Excel. Une Series, en revanche, est une structure de données unidimensionnelle, semblable à une liste ou une colonne d'un DataFrame. Que ce soit les Series ou les DataFrames, ils ont tous les deux des Index. Si l’on ne spécifie pas d’index à la création de nos DataFrames ou Series, un index par défaut allant de 0 à la taille de notre tableau. Ainsi chaque ligne de notre DataFrame ou notre Serie dispose d’un index.
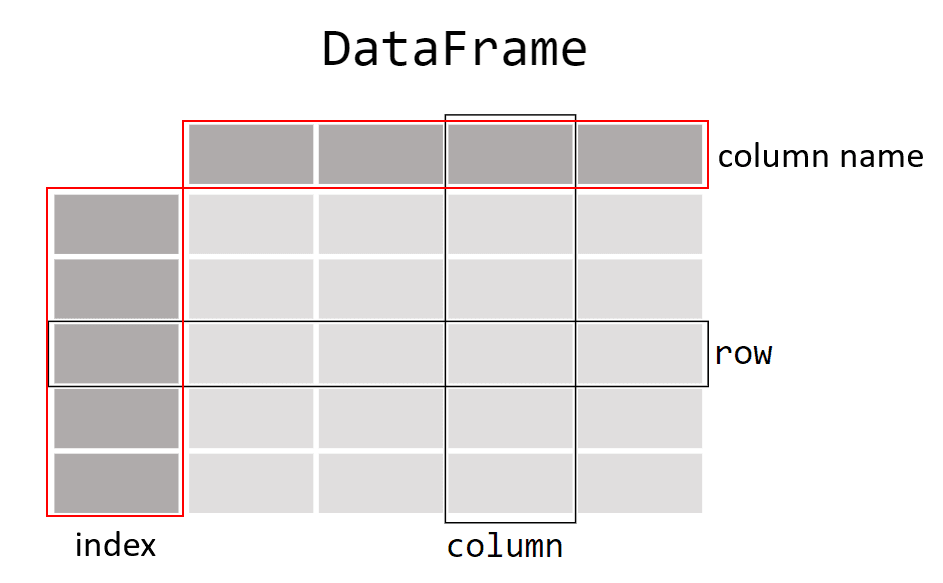
Voici un exemple de création d'un DataFrame avec des données financières :
import pandas as pd
data = {
"date": ["2022-01-01", "2022-01-02", "2022-01-03", "2022-01-04"],
"close": [150.0, 152.0, 153.0, 154.0],
"volume": [1000, 1200, 1300, 1250],
}
df = pd.DataFrame(data)
print(df) # Affiche le DataFrame
print(df.index) # Affiche nos Index
print(df["close"]) # Affiche la Serie "closeé
Dans cet exemple, nous avons créé un dictionnaire contenant trois listes de même longueur : date, close et volume. Ces listes représentent respectivement les dates, les prix de clôture et les volumes d'un actif financier. Nous utilisons ensuite la fonction pd.DataFrame() pour créer un DataFrame à partir de ces données. Notez comment nous accédons à différentes composantes du DataFrame dans les print.
Manipulation et analyse des données financières avec Pandas
Pandas offre de nombreuses fonctionnalités pour manipuler et analyser les données financières. Voici quelques exemples courants :
Sélectionner des lignes ou des colonnes
Voici des exemples qui vont permettre de sélectionner des colonnes, des lignes, des valeurs ou plusieurs colonnes.
close_column = df["close"]
print(close_column)
first_row = df.iloc[0]
print(first_row)
first_close = df.iloc[0]["close"]
print(first_close)
close_volume_columns = df[['volume', 'close']]
print(close_volume_columns)
Pour sélectionner des lignes en fonction d'une condition, vous pouvez utiliser des opérations de comparaison sur les colonnes du DataFrame. Par exemple, pour sélectionner toutes les lignes dans lesquelles le volume est supérieur à 1210:
best_volume_rows = df.loc[df['volume'] > 1210]
print(best_volume_rows)
Lecture de données à partir de fichiers CSV ou Excel
Dans la pratique, les données financières sont souvent stockées dans des fichiers CSV ou Excel. Les fichiers CSV sont des textes avec des données représentées en tableau. Chaque donnée est séparée par un séparateur comme une virgule par exemple. Pandas facilite la lecture de ces fichiers et la création de DataFrames à partir de leurs données :

Vous trouverez ici https://github.com/CryptoRobotFr/python-pour-la-finance/blob/main/APPL_1D.csv un fichier CSV représentant le prix de l’action APPL jours par jours. Vous pouvez le télécharger fichier qui se trouve sur GitHub et le placer dans le même dossier que votre fichier python.
Pour télécharger le fichier, il suffit de cliquer sur l’icône de téléchargement (entouré en rouge sur l’image ci-dessus)
GitHub est une plateforme de développement de logiciels permettant aux développeurs de collaborer sur des projets, de suivre et de contrôler les changements dans le code. C’est également ici que sont publiés la plupart des codes “open source” notamment ceux proposés par Crypto Robot.
Ces données sont dans le format OHLCV. C’est un format fréquemment utilisé pour représenter le prix d’un actif pour une période donnée (ici toute les 4 heures) : le prix d’ouverture (Open), le prix le plus haut au cours de la période (High), le prix le plus bas (Low), le prix de clôture (Close) et enfin le Volume.
Une fois le fichier csv téléchargé et placé dans votre dossier de travail, vous pouvez lire votre fichier CSV afin de le stocker dans un DataFrame. Pour cela :
df = pd.read_csv("APPL_1D.csv)
print(df)
Dans ce cas, nous avons lu le fichier pour stocker le contenu dans la variable df, cela revient à faire ce que l’on avait fait lors de la création de notre premier DataFrame comme ceci :
data = {
"date": ["2022-01-01", "2022-01-02", "2022-01-03", "2022-01-04"],
"close": [150.0, 152.0, 153.0, 154.0],
"volume": [1000, 1200, 1300, 1250],
}
df = pd.DataFrame(data)
Sauf que dans ce cas, au lieu de spécifié nos données “à la main”, elles viennent directement d’un fichier.
Exploration et manipulation des données financières
Une fois que vous avez stocké vos données financières dans un DataFrame Pandas, vous pouvez facilement explorer et manipuler ces données. Par exemple, vous pouvez calculer des statistiques descriptives, filtrer les données selon certaines conditions.
Explorer les données financières
Dans un premier temps, une bonne pratique lorsque vous exploitez un fichier, est d’explorer rapidement les données de ce fichier afin de s’assurer de la qualité des données. En effet dans la réalité vos données seront rarement parfaites et prêtes pour analyse. Il faudra souvent “nettoyer” vos données. Pour explorer vos données rapidement il existe la méthode describe().
df = pd.read_csv("APPL_1D.csv")
print(df.describe())
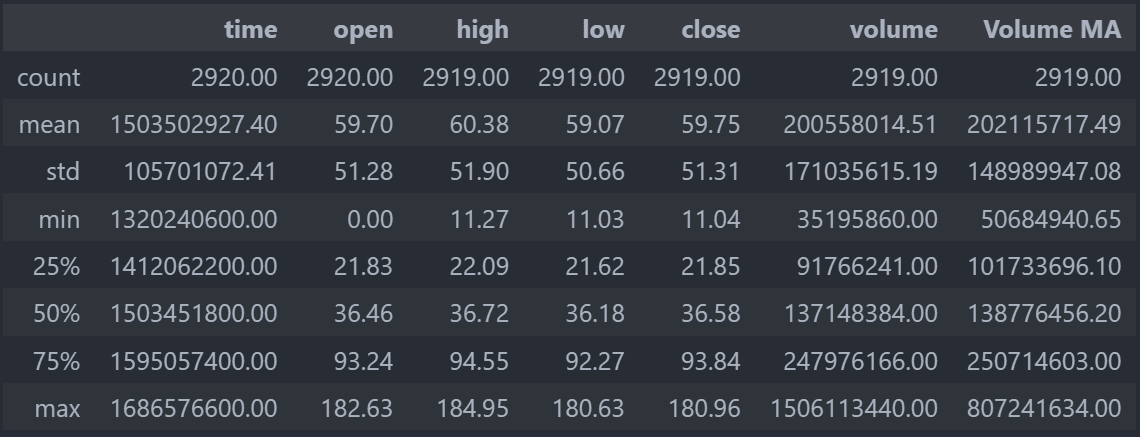
Il est probable que votre affichage comporte des notations scientifique avec par exemple e+03, cela signifie dans ce cas x10 à la puissance 3, soit x1000. Cela est notamment utile lorsque l’on a des nombres très petits ou très grands.
Dans notre cas cela nuit à notre analyse donc vous pouvez insérer cette ligne de code par exemple en dessous de l’importation de pandas afin d’arrondir tous les nombres à 2 chiffres après la virgule:
pd.set_option('display.float_format', lambda x: '%.2f' % x)
La méthode describe() nous donne pour chaque colonne plusieurs informations. La ligne count représente le nombre d’occurrences, les lignes 25%, 50% et 75% représentes ce qu’on appelle des quantiles, nous ne rentrerons pas en détail ici. La ligne std représente l’écart type (standard deviation). Les autres lignes sont assez explicite par leurs noms (mean, min, max).
Avec un peu d’observation nous pouvons remarquer plusieurs “problèmes” dans nos données.
Le premier étant la présence de la colonne Volume MA dont nous ne connaissons pas la signification et qui n’a donc aucun intérêt.
Le deuxième est que les colonnes time et open ont 2920 occurrences alors que les autres colonnes n’en n’ont que 2919. Il faudra trouver la ligne ou les autres colonnes n’ont pas de valeurs.
Ensuite la colonne time est au format numérique que l’on ne peut pas comprendre.
Enfin si l’on regarde dans le détail on voit que le minimum de la colonne open est de 0. Cela semble peu probable que le prix d’ouverture de l’action APPLE ai été à 0$ à un moment.
Dans un premier temps il faut trouver où se trouve nos valeurs qui n’ont pas d’occurrences. Pour cela on peut chercher les valeurs null de la colonne close par exemple:
print(df.loc[df["close"].isnull()])
Pour enlever la colonne Volume MA vous pouvez exécuter le code suivant:
df = df.drop("Volume MA", axis=1)

Nous remarquons ici que c’est la dernière ligne (avec l’index 2919) qui contient un valeur pour la colonne time et open mais pas pour les autres (les valeurs NaN signifient “Not a Number”). Cela est surement du au fait que au moment de la récupération des données, la journée n’était pas clôturée et donc que le prix le plus haut, le plus bas, le volume ainsi que le prix de clôture n’était pas disponible. Le plus simple ici pour éviter des problèmes par la suite est de supprimer cette ligne. Pour supprimer la ligne avec l’index 2919:
df = df.drop(2919)
- Nous pouvons remarquer que la colonne time comprend des nombres très grands. Après un peu de recherche nous pouvons comprendre que ce sont des dates en format timestamp. Les nombres en question représente le nombre de seconde passée depuis 1970. Heureusement pandas possède une méthode pour convertir ces nombres en dates.
df["time"] = pd.to_datetime(df["time"], unit='s')
print(df["time"])
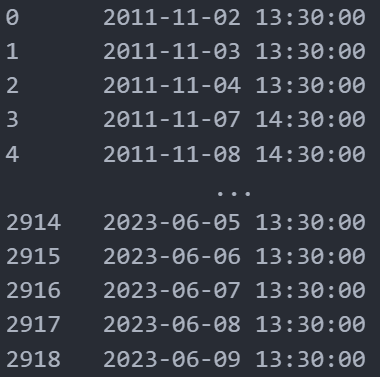
Nous avons maintenant des dates lisibles. Ce que nous pouvons faire maintenant c’est remplacer nos index par déaut (1, 2, 3…). Une fois que cela sera fait nous n’aurons plus besoin de notre colonne time donc nous pourrons la supprimer. Pour cela:
df = df.set_index(df['time'])
del df['time']
Le fait que nos dates soient en index nous permet par exemple de selectionner une ou ou plusieurs lignes grâce aux dates très simplement:
print(df.loc["2023-05-04"]) # Afiche les valeurs au 4 mai 2023
print(df.loc["2023-03"]) # Afiche toutes les valeurs du mois de mars 2023
print(df.loc["2023-03-03":"2023-03-15"]) # Afiche les valeurs au 3 mars au 15 mars 2023
Créer de nouvelles colonnes à partir des colonnes existantes
Pandas vous permet de créer aisément de nouvelles colonnes en fonction des colonnes existantes. Par exemple, vous pouvez créer une colonne qui représente la moyenne entre le prix d’ouverture et de clôture :
df["mean_open_close"] = (df["open"] + df["close"]) / 2
print(df["mean_open_close"])
Ce qu’il faut bien comprendre ici, c'est que nous appliquons l’opération sur toutes les lignes. Vous n’avez pas besoin de faire une boucle pour appliquer ce changement à chacune des lignes. Les boucles en Python ont tendance à être lente en temps d’exécution, alors lorsqu’il est possible de les éviter, if faut en profiter.
Calculer des statistiques descriptives
Pandas propose des fonctions pour calculer des statistiques descriptives sur vos données financières. Par exemple, vous pouvez calculer la moyenne, la médiane, l'écart-type, et d'autres statistiques sur les prix des actions de chaque entreprise.
# Calculer des statistiques descriptives pour chaque colonne
mean_prices = df["close"].mean()
median_prices = df["close"].median()
std_prices = df["close"].std()
print("Moyenne des prix de clôtures:", mean_prices)
print("Médiane des prix de clôtures:", median_prices)
print("Écart-type des prix de clôtures:", std_prices)
Calculer une moyenne mobile
Une moyenne mobile est une moyenne du prix roulante. Cela signifie par exemple que pour chaque date la valeur de la moyenne mobile sera la moyenne des 50 dernières dates. Pour calculer des valeurs roulantes avec pandas on utilise rolling(50) suivi de l’opération que l’on souhaite faire. Pour calculer la moyenne mobile des 50 derniers jours vous utiliserai rolling() suivi de mean().
df["moving_average"] = df["close"].rolling(50).mean()
Calculer les rendements et la volatilité
Après avoir chargé et préparé les données, vous pouvez effectuer diverses analyses financières. Par exemple, vous pouvez calculer les rendements quotidiens et la volatilité de votre actif. La volatilité est une mesure du risque associé à un investissement et est généralement calculée comme l'écart-type des rendements sur une période définie.
Voici un exemple de calcul des rendements quotidiens et de la volatilité sur une fenêtre glissante de 30 jours à l'aide de Pandas :
# Calculer les rendements quotidiens
df["daily_returns"] = df["close"].pct_change()
print(df["daily_returns"].head())
# Calculer la volatilité sur 30 jours glissants
df["volatility"] = df["daily_returns"].rolling(window=30).std()
print(df["volatility"].head())
Dans cet exemple, nous utilisons la méthode pct_change() pour calculer les rendements quotidiens à partir des prix des actions. Ensuite, nous utilisons la méthode rolling() pour créer une fenêtre glissante de 30 jours, suivie de la méthode std() pour calculer l'écart-type (c'est-à-dire la volatilité) des rendements sur cette fenêtre glissante.
Notez que les premières 29 lignes de la colonne volatility_30 contiendront des valeurs NaN (Not a Number), car il n'y a pas suffisamment de données pour calculer la volatilité sur 30 jours pour ces lignes. La méthode head() permet d’afficher les 5 premières lignes.
Trier les données
Pour trier les données selon une colonne, vous pouvez utiliser la méthode sort_values() sur votre DataFrame. Par exemple, pour trier les données par ordre croissant de volatilité sur 30 jours:
df["daily_returns"] = df["close"].pct_change()
df["volatility"] = df["daily_returns"].rolling(window=30).std()
print(df.sort_values(by="volatility", ascending=True))
print(df.sort_values(by="daily_returns", ascending=True))
Dans cet exemple, nous commencer par créer 2 nouvelles colonnes à notre DataFrame df. Nous affichons ensuite simplement notre DataFrame **df** en allant de la volatilité la plus faible à la plus élevée. Puis nous affichons les journées ayant eu le plus de rendements de la plus faible à la plus élevée.
Maîtriser ses données
Pandas est une librairie très complète pour laquelle nous ne pourrons pas découvrir toutes les fonctionnalités.
Ce qu’il faut savoir c’est qu’à peu près toute manipulation de données est possible grâce à Python et la librairie Pandas, les limites seront vos capacités techniques mais aussi et surtout vos capacités algorithmiques. Ce que l’on veut dire ici, c'est que la plus grosse difficulté est souvent de savoir exactement ce que l’on souhaite faire afin de rechercher l’information sur internet ou sur la documentation officielle Pandas. ChatGPT est aujourd’hui un super outil pour vous aider là-dessus.
Ce qui va donc être clé, comme nous vous l’avons déjà dit, sera de s’entraîner avec des cas pratiques. C’est pour cela que nous vous proposons un exercice d’application pertinent pour apprendre, mais c’est encore mieux si vous vous entrainez sur vos propres données / problématiques.
Exercice d’application : le Titanic
Pour cette exercice nous allons analyser les données liées au naufrage du titanic. Vous trouverez via ce lien https://github.com/CryptoRobotFr/python-pour-la-finance/blob/main/TITANIC.csv un fichier CSV représentant chacun des passagers du titanic avvec notamment leurs noms, leurs sexes, leurs classes (Pclass), leurs âges ainsi que d’autres informations.

Instructions
Commencer par télécharger le fichier CSV, placer le dans votre répertoire, importer pandas dans votre fichier python et importer votre CSV sous la forme de DataFrame avec:
df = pd.read_csv('TITANIC.csv')
Attention pour cette exercice vous aurez besoin de méthodes que nous n’avons pas encore vu comme value_counts() ou groupby(), le but est que vous puissiez faire des recherches par vous même.
Questions
- Affichez les 10 premières lignes de ce dataset pour avoir un aperçu des données.
- Quelle est la taille de ce dataset ? (Combien de lignes et de colonnes)
- Combien y a-t-il de passagers dans chaque classe (Pclass) ?
- Quel est l'âge moyen des passagers ? Quel est le nom du passager le plus jeune ? Et le plus âgé ?
- Combien de passagers ont survécu et combien sont décédés ?
- Combien de femmes et combien d'hommes se trouvaient sur le Titanic ?
- Combien de femmes ont survécu ? Et combien d'hommes ?
- Quelle est la proportion de survie par classe ?
- Créez une nouvelle colonne 'FamilySize' qui est la somme des colonnes 'SibSp' (nombre de frères et sœurs ou époux) et 'Parch' (nombre de parents ou d'enfants).
- Quel est le nom de la personne n’ayant pas survécu qui avait le plus de membre dans sa famille ?
Un exemple de correction se trouve ici: https://github.com/RobotTraders/Python_For_Finance/blob/main/exercise_correction_chapter_5.ipynb