Créer des Indicateurs de Trading par Programmation Génétique

La programmation génétique crée des indicateurs de trading par sélection naturelle. Concept, implémentation Python avec DEAP et pièges d'overfitting.

cos(sub(high, mul(close, open))) — aucun analyste technique n'écrirait cette formule. Le RSI, le MACD, les bandes de Bollinger : tous ont été conçus par des humains. Cette formule, elle, a été inventée par un algorithme qui combine des opérations mathématiques et des données de prix sans aucune intuition humaine comme point de départ.
C'est le principe de la programmation génétique (genetic programming, GP), une branche de l'intelligence artificielle qui emprunte ses mécanismes à la théorie de l'évolution de Darwin. Pas de réseau de neurones, pas de données étiquetées : juste de la sélection naturelle appliquée à des formules mathématiques.
Le concept est séduisant. Mais plus un algorithme est libre d'explorer, plus la frontière entre découverte et illusion statistique devient fine. Voyons comment le mécanisme fonctionne, comment l'implémenter en Python, et ce qu'il faut surveiller pour ne pas confondre un bon indicateur avec un artefact du passé.
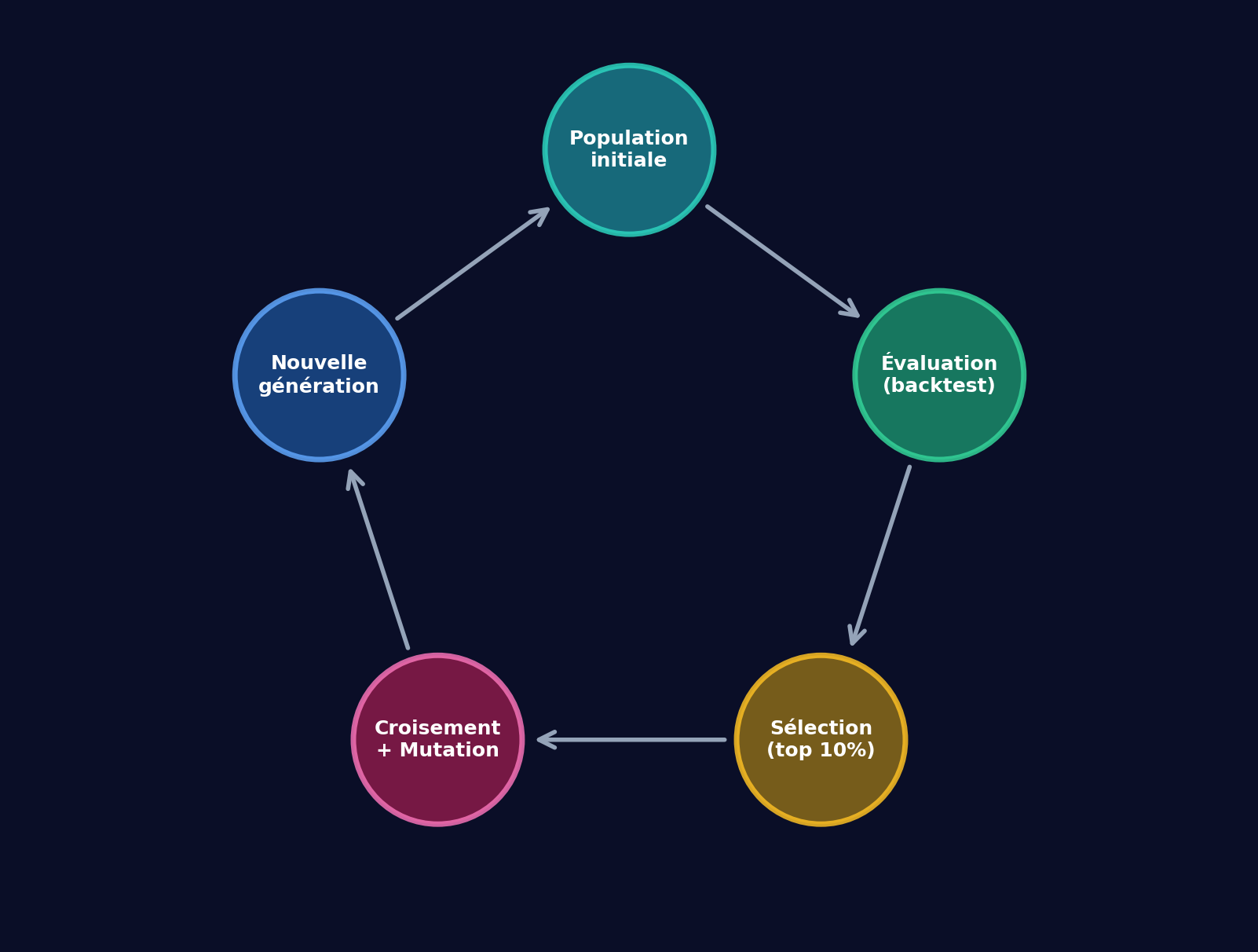
Le cycle évolutif : de la formule aléatoire au champion
Comme dans la théorie de l'évolution de Darwin, tout commence par une population : des milliers de formules mathématiques générées aléatoirement. Chacune est un arbre d'opérations (additions, soustractions, cosinus...) appliquées à des données de prix. Certaines sont simples, d'autres complexes, et la grande majorité ne vaut rien. Mais c'est le point de départ.
Chaque formule est utilisée comme indicateur de trading dans une même stratégie, puis backtestée sur des données historiques. Le résultat du backtest donne un score, la fitness, qui mesure sa qualité. Les formules les mieux classées survivent (le top 10 %, par exemple), les autres sont éliminées.
Les survivantes se reproduisent. Le croisement (crossover) mélange des morceaux de deux formules parentes pour en créer de nouvelles, tandis que la mutation modifie aléatoirement une partie d'une formule existante. Ce mélange de recombinaison et de hasard produit une nouvelle population de formules, en principe un peu meilleure que la précédente.
Ce cycle complet (évaluation, sélection, croisement, mutation) constitue une génération. Le processus se répète sur des dizaines de générations. À chaque itération, les formules s'affinent. Au terme de l'évolution, la formule la plus performante est le champion : elle est alors testée sur des données out-of-sample (que l'algorithme n'a jamais vues) pour vérifier si elle se généralise. Avec des populations de 15 000 formules et 20 générations, le processus représente 300 000 backtests, ce qui explique les jours de calcul.
Le schéma ci-dessous résume ce cycle évolutif :
Programmer l'évolution en Python avec DEAP
En pratique, la librairie DEAP (Distributed Evolutionary Algorithms in Python) gère l'ensemble du cycle décrit plus haut : population, évaluation, sélection, croisement, mutation. La première étape consiste à définir les briques de base que l'algorithme pourra assembler pour construire ses formules.
Dans l'exemple ci-dessous, appliqué au crypto, les entrées sont les prix OHLC (open, high, low, close) et les opérations disponibles sont l'addition, la soustraction, la multiplication, le cosinus et le sinus. D'autres entrées (indicateurs techniques, prix de plusieurs actifs) et d'autres opérations sont possibles ; c'est l'un des paramètres à expérimenter.
from deap import gp
import operator, math
# Définir les primitives (opérations disponibles)
pset = gp.PrimitiveSet("MAIN", arity=4) # 4 inputs : open, high, low, close
pset.addPrimitive(operator.add, 2)
pset.addPrimitive(operator.sub, 2)
pset.addPrimitive(operator.mul, 2)
pset.addPrimitive(math.cos, 1)
pset.addPrimitive(math.sin, 1)
pset.renameArguments(ARG0='open', ARG1='high', ARG2='low', ARG3='close')
# Un individu généré aléatoirement pourrait ressembler à :
# cos(sub(high, mul(close, open)))
# → une formule qu'aucun analyste technique n'aurait écrite
À partir de ces briques, DEAP génère la population initiale, puis lance le cycle d'évolution. À chaque génération, chaque formule est compilée en fonction Python, appliquée barre par barre sur les prix, et backtestée. La métrique de fitness peut être le rendement brut, le ratio de Sharpe (rendement ajusté au risque), le drawdown maximum, ou une combinaison de critères. Le backtesting repose souvent sur vectorbt (librairie de backtesting vectorisé), indispensable pour traiter des milliers de backtests dans un temps raisonnable.
L'overfitting : le piège structurel de la programmation génétique
La GP est, par construction, une machine à overfitting (surapprentissage). Son objectif est de trouver la formule qui performe le mieux sur des données passées. Plus le nombre de générations augmente, plus l'algorithme risque de découvrir une formule qui colle parfaitement à l'historique sans capturer de signal réel.
Tester le champion sur des données out-of-sample est nécessaire, mais insuffisant. Si l'évolution est relancée dix fois et que le meilleur résultat parmi ces dix runs est sélectionné, c'est le jeu de test lui-même qui devient surapprêté. Ce phénomène, le data snooping (fouille de données répétée), reste invisible dans les métriques. Le biais du survivant (tendance à ne voir que les résultats gagnants) amplifie le problème : le classement final ne montre que les formules qui ont survécu, pas les milliers qui ont échoué.
Signaux d'alerte et garde-fous contre le surapprentissage
Quelques indicateurs permettent de repérer un champion surapprêté : une fitness qui progresse en entraînement mais stagne sur de nouvelles données, un ratio de Sharpe élevé avec très peu de trades (l'indicateur a trouvé des anomalies ponctuelles plutôt qu'un signal récurrent), ou une formule excessivement complexe. Un arbre de 50 opérations imbriquées capture du bruit, pas du signal.
Les garde-fous existent. La validation walk-forward (validation glissante), explorée dans notre newsletter sur skfolio, découpe les données en fenêtres successives et teste l'indicateur sur chacune, simulant un déploiement progressif. Limiter la profondeur des arbres force l'algorithme vers des patterns simples, plus susceptibles de se généraliser. Tester le champion sur plusieurs actifs et plusieurs périodes ajoute un filtre : un indicateur qui ne fonctionne que sur un seul marché est probablement un artefact statistique.
La programmation génétique ouvre une voie différente du machine learning classique. Au lieu d'entraîner un modèle sur des patterns prédéfinis, elle laisse l'algorithme inventer ses propres formules par sélection darwinienne. Le résultat est un indicateur qu'aucun humain n'a conçu, potentiellement capable de détecter des patterns que l'analyse technique traditionnelle ne cherche même pas.
La leçon dépasse la GP : tout outil d'optimisation suffisamment puissant trouvera des patterns dans n'importe quelles données, y compris aléatoires. La différence entre une découverte et un artefact ne se lit pas dans le backtest ; elle se lit dans la rigueur du protocole de validation.
La librairie DEAP est le point d'entrée pour quiconque souhaite expérimenter. Taille de population, nombre de générations, profondeur des arbres : chaque paramètre est à calibrer selon l'actif et la période ciblés.
Bonne évolution !
Commentaires ()