Détection de Régimes sur Bitcoin : Adapter Sa Stratégie de Trading

Deux méthodes Python pour détecter les régimes de marché sur Bitcoin et adapter automatiquement sa stratégie de trading algorithmique.

Un bot de trading affiche des gains réguliers pendant deux mois. Puis, sans aucune modification, il commence à perdre. Même code, mêmes paramètres. Ce qui a changé, c'est le comportement du marché lui-même : il est passé d'une phase où les prix montaient avec régularité à une phase où ils oscillent sans direction claire. Le bot, lui, continue d'appliquer la même logique dans un environnement qui n'a plus rien à voir.
C'est un problème récurrent du trading algorithmique, qui grignote le capital : une stratégie qui fonctionne bien dans un type de marché perd de l'argent dans un autre. Une stratégie de momentum (suivi de tendance) performe quand le marché a une direction claire, mais se fait découper quand il oscille dans un range. Une stratégie de mean reversion (retour à la moyenne) fait exactement l'inverse. Trouver une seule stratégie qui fonctionne partout est pratiquement impossible. La vraie question n'est pas "quelle est la meilleure stratégie ?", mais "dans quel mode se trouve le marché en ce moment ?". C'est exactement ce que la détection de régimes permet de formaliser : identifier le mode actuel pour activer la bonne stratégie au bon moment.
Les trois régimes de marché sur Bitcoin
Bitcoin alterne entre trois grandes phases qu'on peut identifier visuellement sur un graphique. La tendance (haussière ou baissière), c'est une direction claire et soutenue : les prix montent ou descendent avec régularité. Le range, c'est une oscillation latérale : les prix rebondissent entre un support et une résistance sans prendre de direction. Le chaos, c'est de la volatilité élevée sans direction : les prix font de grands mouvements dans tous les sens, souvent lors de crises ou d'événements majeurs.
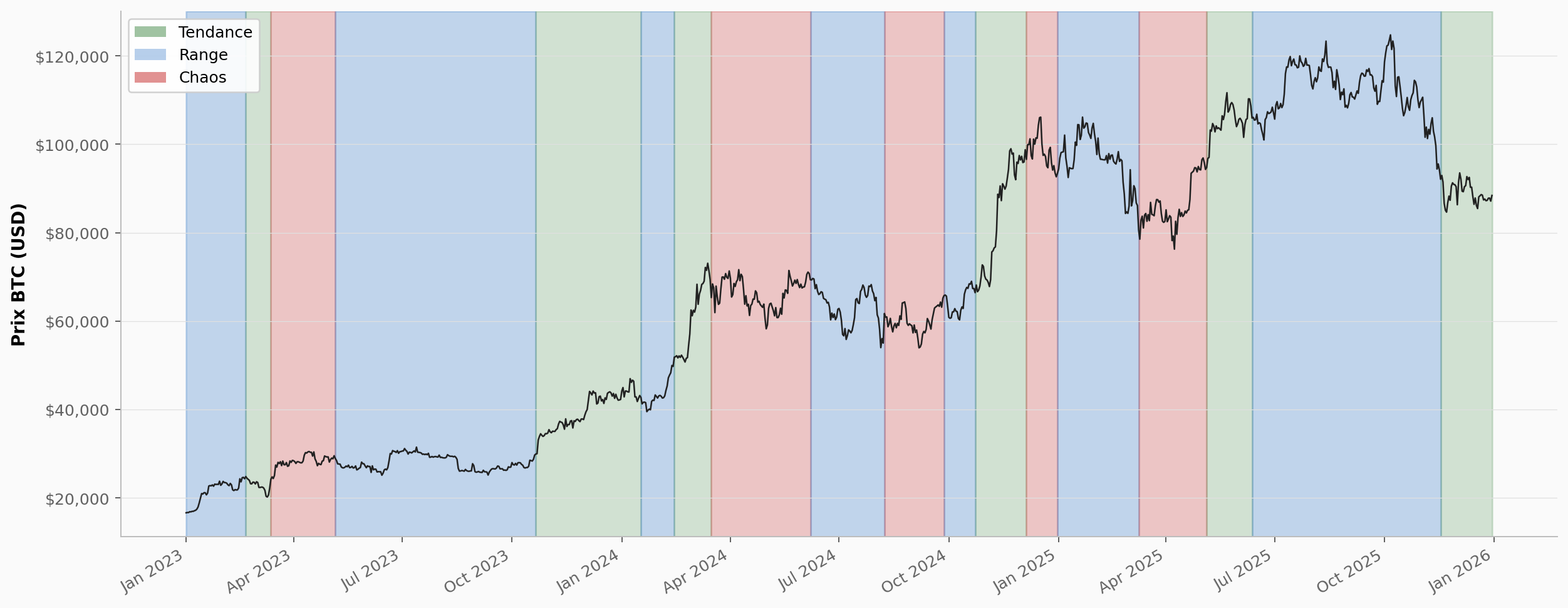
Le graphique ci-dessus illustre cette classification sur trois ans de données BTC. Ces trois phases sont plus faciles à identifier avec le recul qu'en temps réel. L'objectif ici est de formaliser cette intuition visuelle pour qu'un programme puisse la reproduire en temps réel, ou du moins avec un retard raisonnable. Deux méthodes pour y parvenir, de la plus simple à la plus sophistiquée.
Classifier les régimes avec des statistiques glissantes
Deux mesures glissantes permettent de distinguer les trois régimes. La volatilité (l'écart-type des rendements sur une fenêtre) indique l'intensité des mouvements. La direction moyenne (la moyenne des rendements sur la même fenêtre) indique s'il y a une tendance. En croisant les deux, on obtient une classification simple : si la direction est marquée et la volatilité modérée, c'est une tendance ; si la volatilité est faible et la direction absente, c'est un range ; si la volatilité est élevée, c'est du chaos.
En Python avec pandas (la librairie de référence pour la manipulation de données tabulaires), cela tient en quelques lignes :
import pandas as pd
def detect_regimes(prices, window=30, vol_q=0.75, trend_q=0.6):
returns = prices.pct_change()
# Volatilité et direction glissantes
vol = returns.rolling(window).std()
trend = returns.rolling(window).mean()
# Seuils basés sur les quantiles historiques
vol_high = vol.quantile(vol_q)
trend_threshold = trend.abs().quantile(trend_q)
regime = pd.Series("range", index=prices.index)
regime[trend.abs() > trend_threshold] = "tendance"
regime[vol > vol_high] = "chaos"
return regime
Concrètement, vol_q=0.75 signifie que les 25 % de jours les plus volatils sont classés "chaos", et trend_q=0.6 signifie que les 40 % de jours avec la direction la plus marquée sont classés "tendance". Baisser vol_q rend le détecteur plus sensible au chaos ; monter trend_q le rend plus exigeant avant de déclarer une tendance. Ces valeurs par défaut donnent une classification lisible sur BTC, mais chaque stratégie et chaque actif a ses propres dynamiques. Le bon réflexe est de backtester plusieurs combinaisons pour trouver les seuils qui s'accordent avec le système de trading utilisé.
La force de cette approche est sa transparence : on comprend exactement pourquoi chaque jour est classé dans un régime donné.
Détecter les régimes avec un Hidden Markov Model
Le Hidden Markov Model (modèle de Markov caché, ou HMM) repose sur une idée intuitive : le marché se trouve à tout instant dans un "état" qu'on ne peut pas observer directement, mais les rendements et la volatilité qu'on observe en sont des conséquences. Un peu comme la météo : on ne voit pas le système atmosphérique, mais on voit la pluie ou le soleil, et on peut en déduire l'état sous-jacent. Le HMM formalise cette intuition en estimant les états cachés les plus probables à partir des données observées.
En Python, la librairie hmmlearn (dédiée aux modèles de Markov cachés) rend l'implémentation concise :
from hmmlearn.hmm import GaussianHMM
import pandas as pd
def detect_regimes_hmm(prices, n_states=3, vol_window=20):
returns = prices.pct_change().dropna()
vol = returns.rolling(vol_window).std().dropna()
features = pd.DataFrame({
"returns": returns.loc[vol.index],
"volatility": vol
})
# Standardiser pour la stabilité numérique du modèle
scaled = (features - features.mean()) / features.std()
# Le modèle découvre n_states états cachés
model = GaussianHMM(
n_components=n_states, covariance_type="full", n_iter=200
)
model.fit(scaled.values)
states = model.predict(scaled.values)
return pd.Series(states, index=features.index)
Contrairement à la méthode précédente, on ne définit pas manuellement les seuils entre régimes. Le modèle découvre lui-même les frontières à partir des données : il identifie des groupes de jours qui se ressemblent statistiquement et les sépare en états distincts.
Le seul choix structurant est n_states : combien d'états chercher. Mettre n_states=3 ne signifie pas "je veux tendance, range et chaos". Le modèle ne connaît pas ces concepts. Cela signifie "je fais l'hypothèse que le marché alterne entre trois comportements distincts, trouve-les". On part de 3 parce que c'est cohérent avec l'observation visuelle des trois phases, mais c'est une hypothèse à tester. Avec 2, on obtient un découpage plus simple (calme vs agité). Avec 4 ou 5, le modèle cherche des distinctions plus fines, au risque de créer des états sans réalité économique (overfitting). Le vol_window contrôle la résolution de la volatilité en entrée : une fenêtre courte (10-15 jours) réagit vite, une fenêtre longue (30-40) lisse davantage.
La sortie du modèle est une série de numéros d'états (0, 1, 2), pas de labels. Le modèle ne sait pas ce qu'est une "tendance" ou un "range" ; il retourne des groupes statistiquement distincts. C'est à nous de comprendre ce que chaque groupe représente. Voyons ce que cela donne sur nos données BTC :
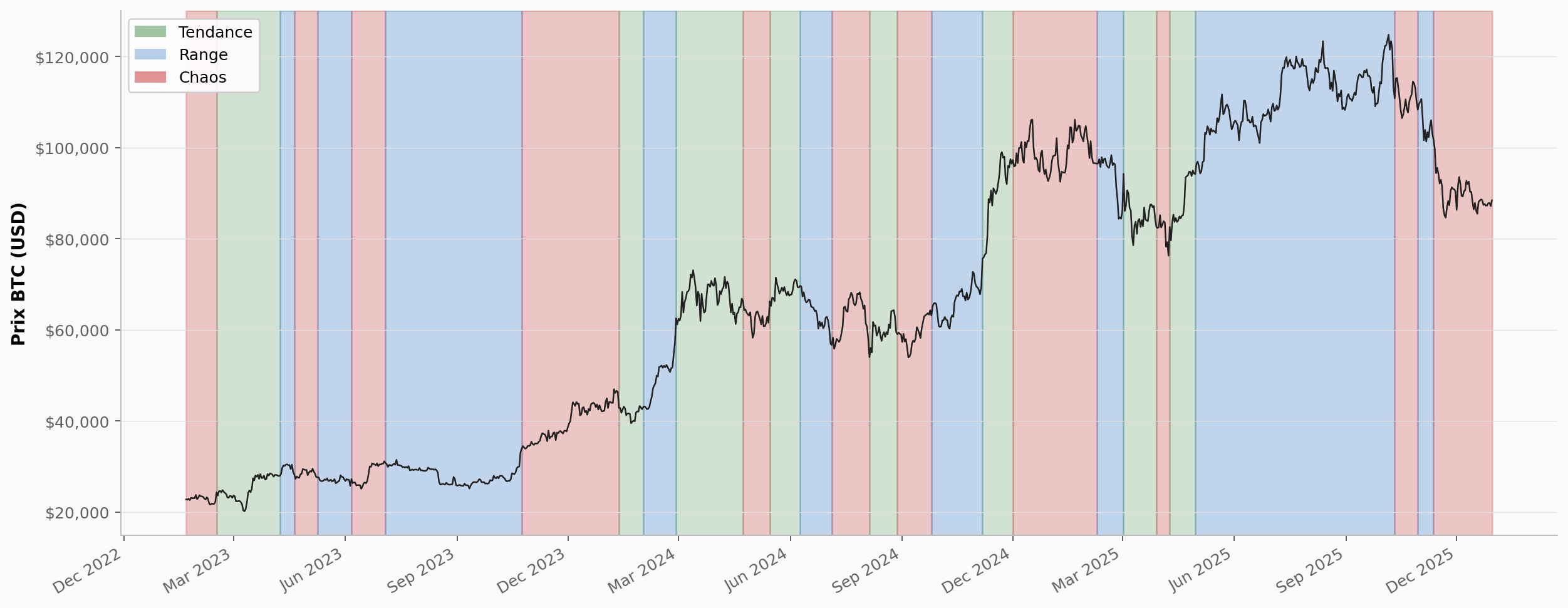
Pour produire ce graphique, on a calculé le rendement moyen et la volatilité moyenne des jours dans chaque état. L'état 0 affichait le rendement moyen le plus élevé (+0,5 % par jour) : on en déduit que c'est notre période de tendance, qu'on voit en vert, comme le rallye de début 2024 (de 42 000 $ à 69 000 $) ou la poussée de novembre 2024 vers 91 000 $. Sa volatilité élevée n'est pas du chaos : elle accompagne les grands mouvements directionnels. L'état 2 avait un rendement faible et la volatilité la plus basse : on en déduit que c'est une période de range, en bleu, comme la phase d'octobre 2023 autour de 27 000 $ ou juin 2024 autour de 66 000 $. L'état 1 se situait entre les deux, avec une volatilité moyenne mais un rendement quasi nul; de la volatilité sans direction : on en déduit que c'est une période de chaos, en rouge, comme début 2023 ou les transitions entre grandes phases.
On remarque que les trois états du HMM ne correspondent pas exactement aux catégories "tendance / range / chaos" définies plus haut. C'est normal : le modèle découvre ses propres catégories en fonction des données, et celles-ci reflètent la réalité statistique de BTC sur cette période (majoritairement haussière). Sur un autre actif ou une autre période, les états découverts auront des caractéristiques différentes.
En comparant avec le graphique de la méthode 1, les grandes phases se recoupent, mais les frontières ne tombent pas au même endroit. Les paramètres du HMM sont aussi moins sensibles : changer vol_q de 0.75 à 0.70 dans la méthode 1 déplace directement les frontières de classification, alors que changer n_states de 3 à 4 dans le HMM ajoute un état sans bouleverser les autres. Le choix entre les deux dépend de ce qu'on cherche : transparence et contrôle (méthode 1) ou découverte automatique (HMM). Le backtesting reste utile dans les deux cas pour valider que les régimes détectés sont exploitables par la stratégie en place.
Regime switching : adapter sa stratégie de trading au régime détecté
Un bot momentum actif en permanence capture les tendances mais accumule des pertes en range, où il réagit à du bruit qu'il interprète comme des signaux directionnels. Un bot mean reversion actif en permanence fait l'inverse. Dans les deux cas, le drawdown (la perte maximale depuis un plus haut) vient principalement des périodes où la stratégie tourne dans un régime qui ne lui convient pas et empile les faux signaux.
L'idée du regime switching est donc d'activer le momentum en tendance, le mean reversion en range, et de passer en cash en chaos. En pratique, cela peut être aussi simple que :
regime = detect_regimes(prices)
if regime.iloc[-1] == "tendance":
signal = momentum_signal(prices)
elif regime.iloc[-1] == "range":
signal = mean_reversion_signal(prices)
else:
signal = 0 # cash
On récupère le régime du jour le plus récent et on sélectionne le signal correspondant. momentum_signal et mean_reversion_signal représentent les fonctions de stratégie propres à chaque système ; en phase de chaos, on reste en cash (signal à 0). Le gain n'est pas nécessairement un rendement brut supérieur, mais un meilleur Sharpe ratio (le rendement rapporté au risque pris) et un drawdown réduit. On n'a pas amélioré une stratégie en particulier, mais plutôt la méta-gestion : on évite d'utiliser la mauvaise au mauvais moment.
Limites de la détection de régimes
Aucune méthode n'est parfaite : il faut accepter qu'un changement de régime sera toujours détecté avec un retard. On sait qu'on est dans une nouvelle phase après qu'elle a commencé, pas avant. Pendant ce lag, la mauvaise stratégie est encore active, et c'est là que le regime switching génère ses propres pertes. Les périodes de transition sont donc souvent la principale source de drawdown dans un système de regime switching.
Pour autant, même un détecteur imparfait fait mieux que "toujours allumé". Réduire l'exposition dans les phases défavorables, même avec un délai, suffit à améliorer le profil de risque. La prochaine étape naturelle serait de lisser les transitions plutôt que de basculer brutalement d'un régime à l'autre ; le filtre de Kalman, par exemple, s'y prête bien.
Commentaires ()